Introduction to Databases Summary
1.1 Data Management in Main Memory?
Data storage is not persistent in main memory. In many applications data must be permanently stored and survive restarts or system crashes.
With the enormous amount of data available today, main memory often isn't large enough to hold all the data to be managed.
1.2 Data Management in Files?
File names simplify addressing data and the operating system already provides directory hierarchies to support the grouping of files.
However, the File System does not enforce an explicit format or model of the data inside a file. Errors in the read/write process to a file can make the data unusable.

The file system does not support searching for data written inside of files. This functionality would need to be provided by a separate programm.
Other problems:
limited support to synchronize multiple, concurrent file accesses at the same time.
limited support for data recovery and protection against data loss in case of system crashes.
limited support for access control. Users usually see the entire file, its difficult to restrict access to parts of a file.
1.3 Databases!
Requirements on a DBS
Integration: Uniform management of all data needed by applications. Storage of the entire data collection free of reduncancy.
Operations: The DBS provides operations for storing, retrieving and manipulating data.
Data Dictionary: A catalog supports access to the description of data.
Individual User Views: The DBS provides different views for different applications/needs and hides data which is not needed in a specific view.
Monitoring consistency: The DBMS monitors and enforces the correctness of data in case of changes.
Access Control: The DBMS avoids unauthorized accesses.
Transactions: A sequence of update operations is combined to an entity whose effect is stored permanently in the DB.
Synchronisation: The DBMS allows different users to work concurrently with the DBS and guarantees that no unintentional interferences occur.
Data Protection: The DBS supports the recovery of data after system failures.
Architecture of DBS:
Intensional Layer: DB Schema describes possible content, structure or type of data stored in the DBS. Changes are rarely and expensive because all content needs to be adapted to the new Schema.

Extensional Layer: Extend of the DB, actual content, information on objects. Changes very frequently for example over 10'000 transactions per minute.

Database Languages:
Data Definition Language (DDL): Declarations to describe the schema of a database. (eg. "create table", "delete table", commands to specify integrity constraints ...)
Data Manipulation Language (DML): Commands to work with the content of a database.
Query Language: access the database (e.g "select all from x", read only)
Manipulation of the database (eg. "insert", "update", "delete")
Abstract Architecture of DBS:
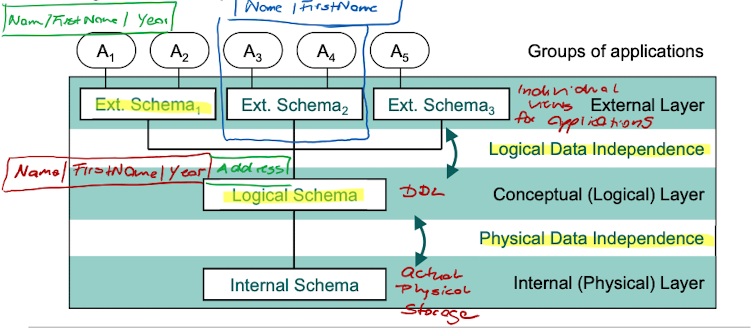
Internal (Physical) Layer: Contains the Structure of data records and index structures. For example the data is indexed by a binary search tree. This layer is essential for the run-time characteristics of the entire DBS
Conceptual (Logical) Layer: Describes object types and its relations but no details on how they are stored. Provides a "holistic" view from a logical perspective on all data which is independend of the different applications.
External Layer: Contains the collection of individual views of all users and applications. A user should only see the data he needs. Bookkeeping needs different data than sales or support.
Physical and Logical Data Intependence
Physical Data Independence: Any modifications of the physical storage architecture (e.g. changing data structures like search trees) does not have any effects on the logical layer.
Logical Data Independence: Changes of the logical schema (e.g. by adding a new attribute to an entity) can be hidden to the application by introducing an appropriate view. This independence might not be guaranteed for all types of modifications. (i.e removing some attribute will obviously affect the views that show it)
2.1 Information Modeling
Overview:
General Task: Find a formal description (model) for the part of the real world to be modeled
Intermediary Step:
Description using natural language (system specification). e.g "The database should store all students together with all the lectures they take"
Description in the relational model: "CREATE Table Student (...)", "CREATE Table Lecture (...)"
Main Phases of DB-Design:
Requirement Analysis => specification of requirements
Conceptual Design => conceptual schema (independed of DBMS)
Logical Design (implementation design) => logical schema (dependend on DBMS)
Physical Design => physical (internal) schema (dependend on DBMS)
Abstraction Concepts:
Classification: Distinguish between the type of an object and the set of objects of a type (also called extend of the type or "ext(...)")
Generalisation and Specialisation, equivalent to Super- and Sub-type in other programming languages.
2.2 Extended/Enhanced Entity Relationship Model
Elements of the ER Model
Entity types

Attribute types
Relationship types

Step 1: Classification
Which types of objects (entity types) should exist?
Which properties (attributes) should describe them?
Which are identifying properties?
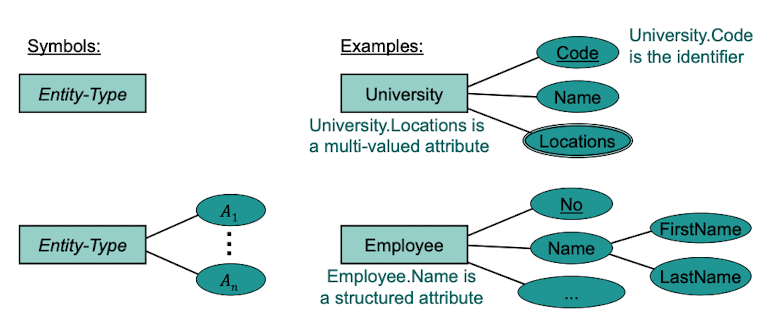
An entity type E designates a set of attributes. A set of objects of the same type (i.e. having the same attributes) are grouped into an entity set or ext(E) (stands for "extend of the type E")
An attribute is a function which maps an entity to a particular property value. (e.g. maps the Entity "Nico" to the Age value "25")
Identifiers:
Identifiers of an entity type E is a set K of single-valued attributes. For two different objects of type E, their respective attribute from K must always differ. In other words: Identifiers must always be unique for their type. Examples: Immatrikulationsnummer for Students
=> Usually, artifical keys are used as identfiers because they do not need to change over the lifetime of their corresponding entities.
Graphical Notation of Entity Tapes:
Step 2: Generalisation and Specialisation
Add structure to the type system by arranging types into a "type hierarchy": Determine wheter there are entity types whose attributes are subsets of other entity types.
Subtypes "inherit" all attributes from their supertypes.
Generalisation hierarchies must not have any cycles! But they also don't have to be trees.
Conditions for Generalisation and Specialisation
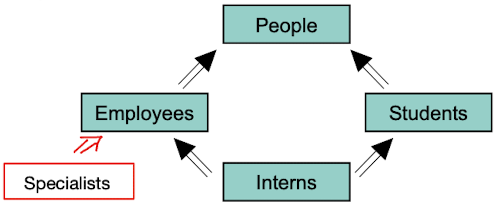
Disjointness constraint: The partitioning of a type E is disjoint if two sets of objects of subtypes of E are disjoint. Else, the partitioning is overlapping. In the image above, the partitioning of "People" is overlapping because "Employees" and "Students" are not disjoint. However, the partitioning of "Employees" is disjoint because "Interns" and "Specialists" are disjoint.
Completeness constraint: The partitioning of E is called total if the union of the specialised object sets yields the object set of E. Else, the partitioning is called partial. In the image above, if all people have a specialisation (e.g there exists no object of type "People" without also being a subtype of it), then it is a total partitioning, also called "complete".
Step 3: Relationship Types
A relationship set of type B also called ext(B) is a subset of the Cartesian product of the involved sets of objects. "ext(E1)" describes the "extend" of the type E1 which is the set of all objects of type E1.
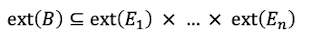
A single binary relation b is defined by an n-tuple
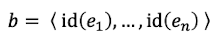
where e1 is the identifier of an object of type E.
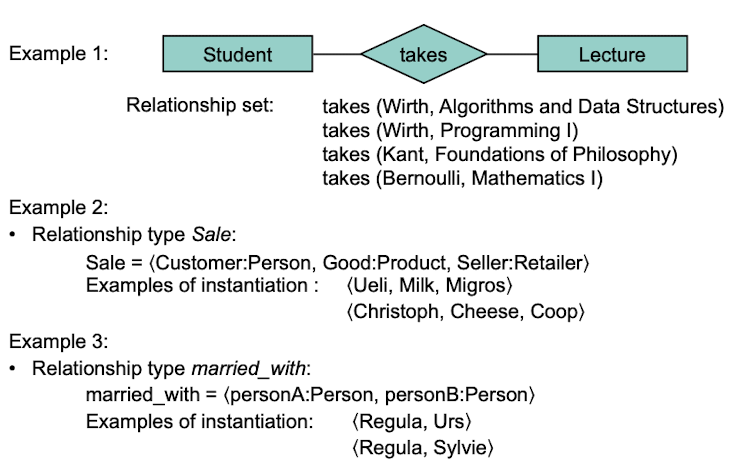
Attributes of Relationship Types
Attributes can be added to relationship types just like with entity types.
Higher-Degree Relationships
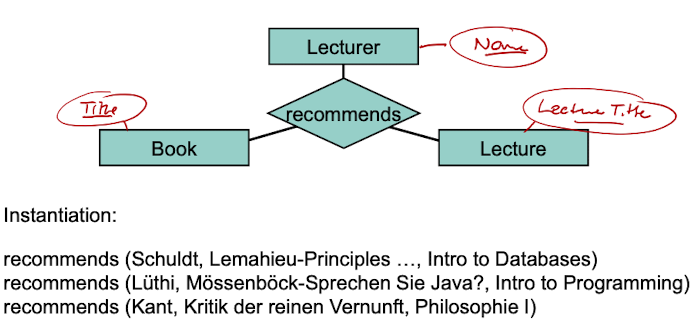
Keys in Relationship Types
A subset K of the union of all keys of the involved entity types is denoted as (candidate) key of the relationship type B. Two different relationships from ext(B) must always have different keys.
If there exist multiple candidate keys, one is selected to be the identifier of B.
Any relationship type with attributes could also be modeled as an entity type.
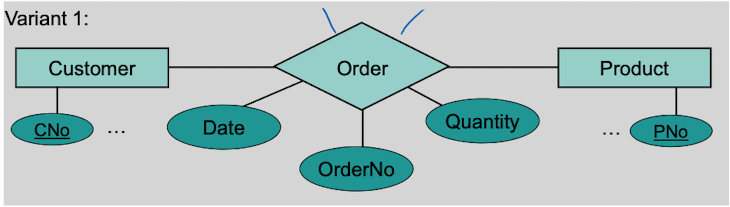
CNo and PNo are the identifiers which together describe the relationship type "Order". However, since the identifier for "Order" needs to be unique, a customer can order a product only once!
Step 4: Cardinality Restrictions
Cardinality constraints are used to limit the number of relationships an entity type can be involved with.
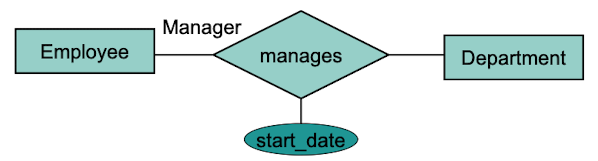
1:1 Relationship
The objects have either none or exactly one relationship with each other.
An Employee can manage at most one Departement but each Department has exactly one manager

m:1 Relationship
Each object on the "many" side (employee) is related to at most one object on the "one" side (department). Usually not the other way around.
Every Employee works in exactly one Departement. Each Department has a minimum of two to unlimited number of employees.

m:n Relationship
Either object can have several relations to the other object.

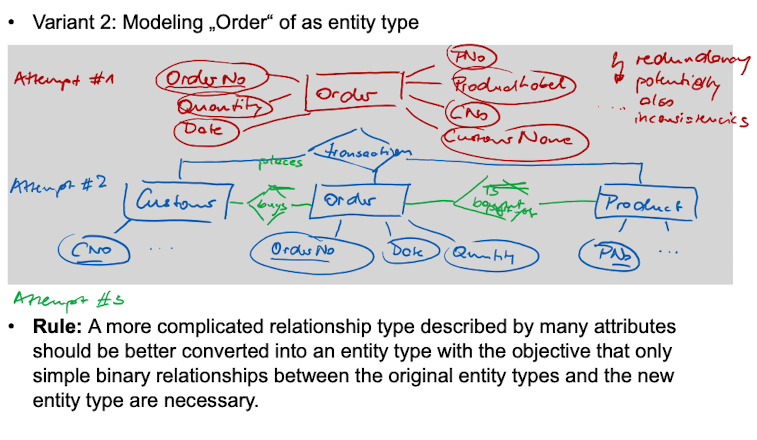
Conversion from n-ary Relationship Types into Entity Types with binary relationship types.
An n-ary relationship type can always be modeled as standalone entity type with only binary relationship types relating to it. A new identifier is needed though.
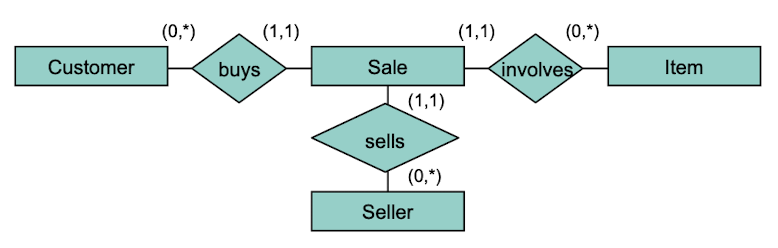
Recursive Relationship Types
A relationship type can connect to the same entity type for two or more times. To do this, role names for the respective role of the entity type must be introduced.
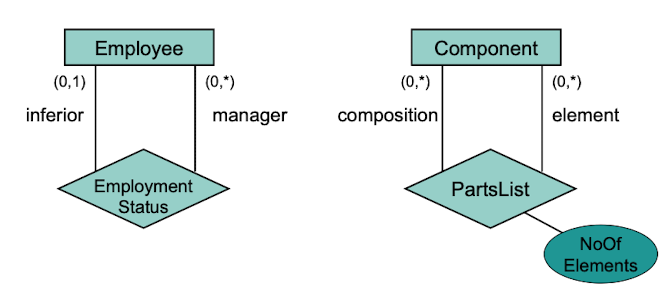
Weak Entity Type
An entity type is called weak if it is in a strict hierarchical relationship to an "owner" entity type. i.e the entity type is not viable on its own.
3.1 The Relational Model
In Relational databases, data is managed in relations (tables). Relations are comprised of sets of tuples (rows). Each tuple has the same set of attributes (columns).
Each attribute has a domain. In First Normal Form the domain is atomic.
In a relation (table), a single attribute (column) or a set of attributes is marked as primary key. The value of this key attribute (set) has to be unique in the extension of each relation. This is called entity integrity.
Relationships between to relations (tables) are possible by enforcing that the values of attributes A of Relation R coincide with the primary keys of another relation (another table). The Attributes referencing a primary key in another table are called foreign keys.
Domain
A Domain is a set of "atomic" values that can not be further subdivided. It can have finite or infinite cardinality (number of elements in the set).
Example:
D1 = Integer
D2 = {red, green, blue, yellow}
D3 = {1 ,2 ,3}
But also sets of encapsulated values of abstract data types or Binary Large Objects (BLOBs). An Essential property is that these values can only be accessed as a whole.
Relation, Relational Schema, Attribute, Extension
Given a set of domains {D1, ... , DM}, a relation R consists of
a schema which is an ordered set of attributes {A1, ... , AM}. In short: sch(R) = {A1, ... AM}. Each attribute has a domain assigned to it. example: dom(A1) = D2
an extension (values) is a subset of the cartesian product of the domains of all attributes of a relational schema. Also written val(R)
Example:
Customers(CID, Name, City, Balance)
"Customer" is a relational schema with an ordered set of attributes. In this case, Name, City and Balance.
Tuples
An Element t of the extension val(R) is a tuple
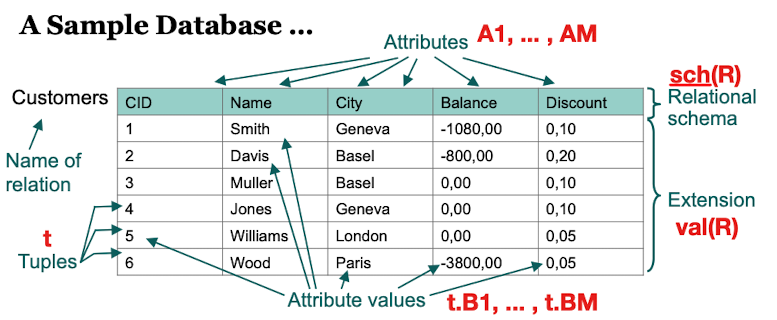
The set of domains contains all values in the table. (Those can not be subdivided)
The relation R (here: relation(Customer)) consists of the relational schema and the extension. In other words: titles and values
The relational schema is an ordered set of attributes (here: CID, Name, City, Balance, Discount)
The Extension val(R) is a subset of all the domains. In other words: is the content of the table.
an Element of the Extension is the tuple t which represents one row in the table.
Remarks:
In the context of database languages, other terms are used instead of the mathematical ones:
Table instead of relation
Columns instead of attribute
Record or row instead of tuple
First Normal Form
The limitation to only atomic domains for attributes is called first normal form (1NF) of the relational model.
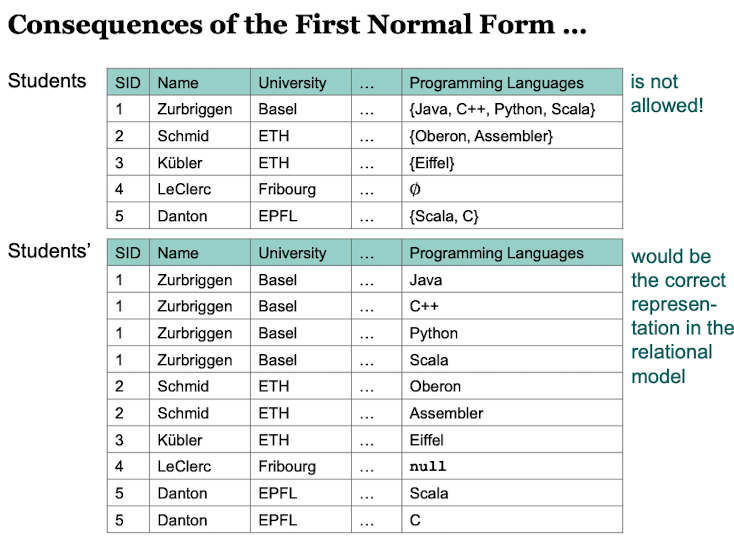
Keys
Candidate Key
A set of attributes of some Relation is called candidate key if for any pair of tuples t, if the attribute values of the tuple are equal, then the tuples themselves are equal.
Example from the image above:
The set of Attributes {Name, University} can not be a candidate key for Student because there could be multiple students with the same name at the same university. However as soon as "SID" is in the set, the set would be a candidate key since there are no two different people with the same SID.
Key attribute
An attribute of a relation that is member of at least one candidate key is called key attribtue.
Primary Key
The primary key of a relation is a dedicated, manually chosen candidate key. The primary key might consist of several attributes.
Foreign Key
A set of attributes F is called foreign key if there exists a relation (table) in which F is primary key.
Null Value
An attribute of a tuple (row) can have a so-called "null value". In this case, the value of this attribute is undefined.
Primary Key Constraint
The attributes of a primary key must not have a null value.
Foreign Key Constraint
For each value of a foreign key, the referenced relation (table) must either contain a tuple with the exact same value as primary key or all values of the foreign key attributes have to be null. In other words: Either the foreign key is primary key in another table, or the foreign key is null.
3.2 Transformation from EERM => Relational Model
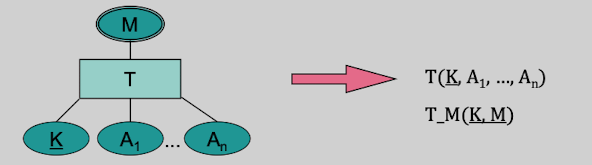
In General, each entity type and each relationshop type is mapped to a relational schema with the same name.
Rule 1: Core Entity Types
Core Entity Types are entity types which are neither a weak entity nor a subtype in type hierarchy
Let E be a core entity type, then E is mapped to relational schema E that contains the primary key K of the entity E and all attributes.
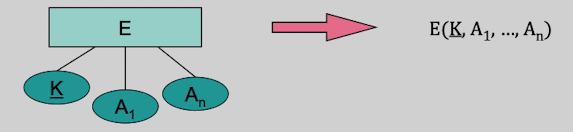
Rule 2: Transformation Rules (Sub and Super Types)
Assume there is the Core Entity Type Person and two sub-types Student and Employee.
2a: Vertical Partitioning
Relation Person contains ext(Person). In other words: The table Person contains all persons, students and Employees. There are different tables for Student and Employee with additional attributes for those entitites.
Person(PID, Name, Age)
Student(PID, Subject) - (PID is primary key and foreign key)
Employee(PID, Department) - (PID is primary key and foreign key)
2b: Horizontal Partitioning
Relation Person contains ext(Person) - ext(Student) - ext(Employee). In other words: The table Person contains only persons which are not Students or Employees. There are different tables for Student and Employee containing the attributes from Person as well as additional attributes for those entities.
Person(PID, Name, Age)
Student(PID, Name, Age, Subject) - (no foreign key)
Employee(PID, Name, Age, Department) - (no foreign key)
Rule 3: Weak Entities
The Weak Entity W has a composite key as primary key consisting of its own primary key A1 and the primary key K from the entity E it depends on.
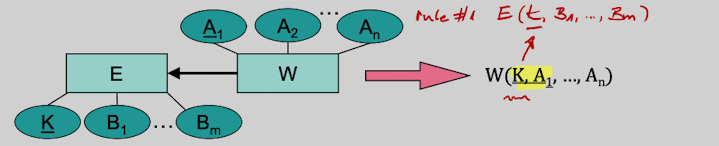
Rule 4: Relationship Types
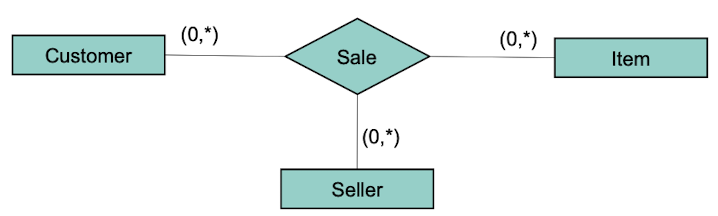
If all edges between R and its Entities has a cardinality restriction of (0,*) or (1,*) then the primary Key is either the composition of all primary keys of those entities or a multi-element-subset of it.
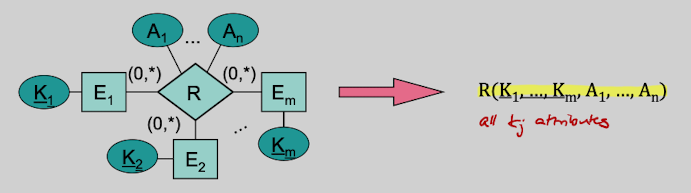
If one edge between R and its Entities has a cardinality restriction of (0,1) or (1,1), then the primary key of that edge becomes a candidate key for R. If multiple edges have have such a restriction, then all primary keys of those Entities become candidate keys.
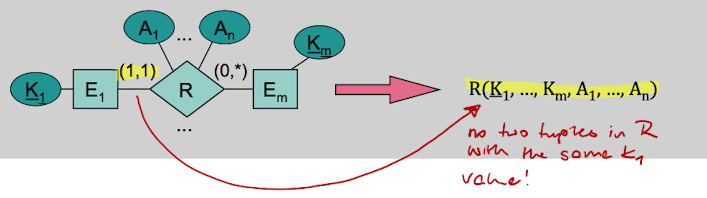
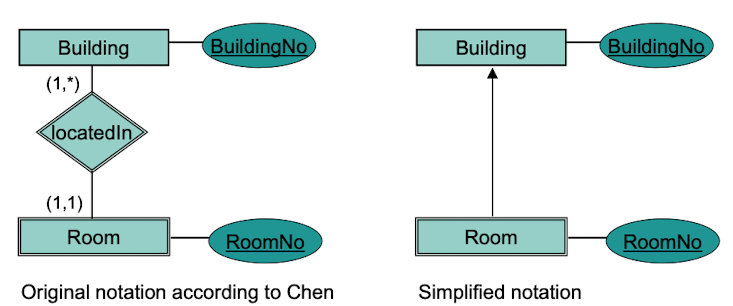
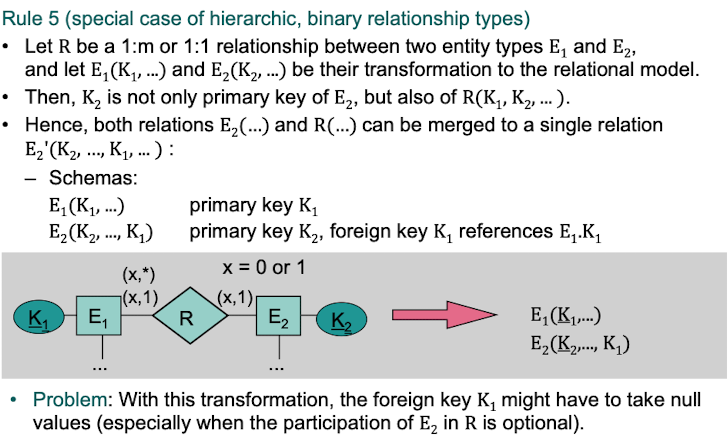
Rule 5: (Special Case of hierarchic, binary relationship types)
If there is a 1:m or 1:1 relationship between two entity types E1 and E2, then the primary key of E2 is also primary of the relationship type between E1 and E2.
Example: A Person owns 0 or more bank accounts and every bank account is owned by exactly 1 Person. Then the relations "Bank Account" and "Owns" can be merged together.
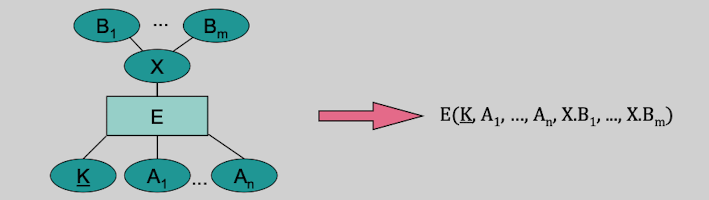
Rule 6a: Structured Attributes
If an Entity has structured Attributes, each "sub-attribute" will be listed separately as independed attibute.
Rule 6b: Multi-Valued Attributes
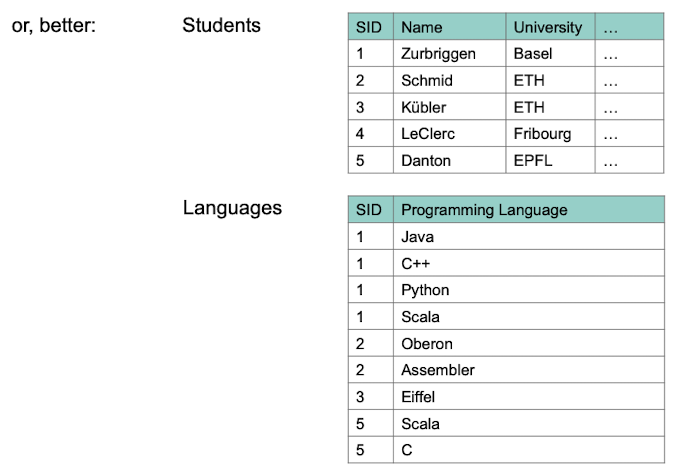
If an Entity has a multi-valued attribute, then each value of the multi-valued attribute is mapped to a schema of that Entity.
Example: University has a multivalued Location attribute with the locations {Basel, Zürich, Bern}
This will be mapped to:
University(ID, Lectures, ...) - normal mapping but locations is left out.
UniversityLocations(ID, Location) - Separate table which is linked to University(...)
4.1 SQL Overview
SQL - Structured Query Language is the standard language for data definition and data manipulation in relational database systems.
SQL consists of two sub-languages, the DDL for data definition and the DML for data manipulation.
SQL contains:
an interactive "stand alone" SQL
Commands for enforcing data integrity and access control.
Commands for physical data organisation (indexes, etc).
Embedded SQL for integration in the most common programming languages (e.g Python)
Integration of SQL in "4th generation language"
4.2 SQL Data Definition Language
Simple Data Definition

Examples:

4.3 SQL Data Manipulation Language
Queries

When executing a Basic SelectBlock,
the cartesian product of all tuples of all relations in the FROM clause is calculated,
the filter specified in the WHERE clause is applied
only the attributes specified in the SELECT clause are returned
Examples:


Complex Search Predicates - BETWEEN AND, LIKE


Test for Null Value / Membership in Set - IS NULL

Nested Select Blocks with "IN" Predicate

Quantified Comparisons - ALL / ANY

Test, whether a Set is empty or not - (NOT) EXISTS

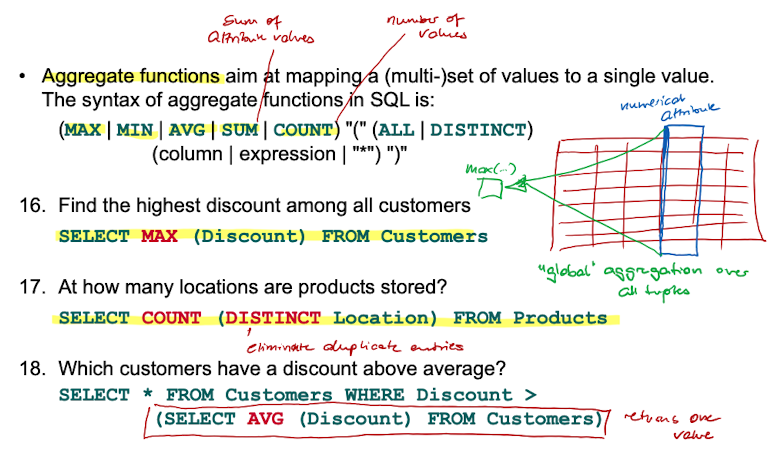
Aggregate Functions - MAX / MIN / AVG / SUM / COUNT

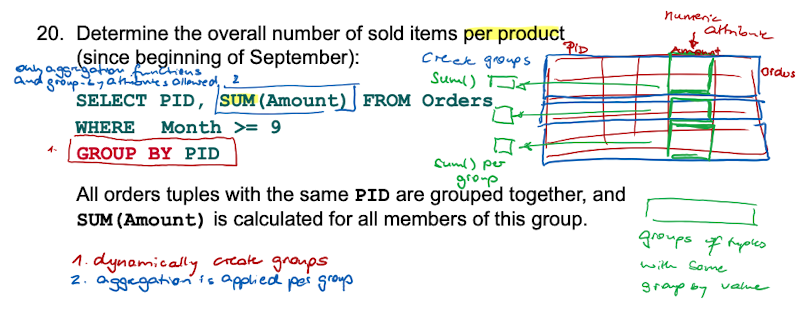
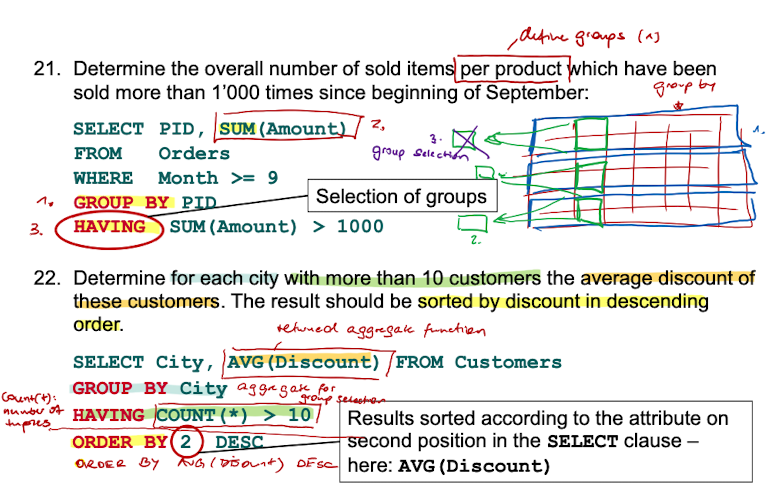
GROUP BY / HAVING
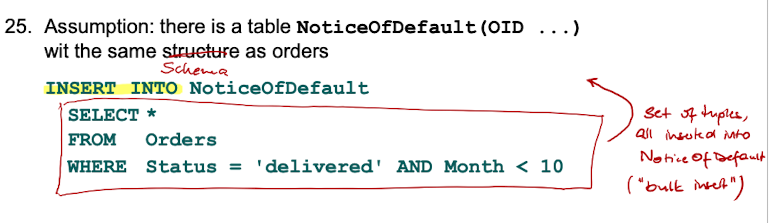
Data Modification - INSERT

UPDATE
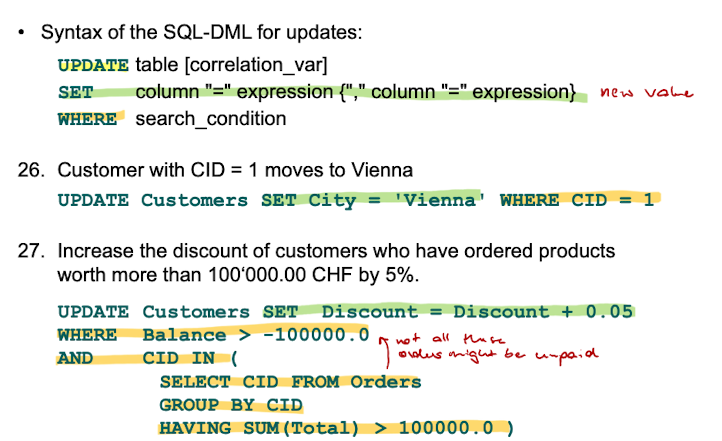
DELETE

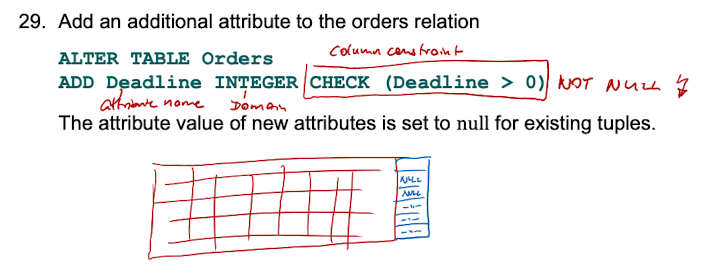
Schema Changes - ALTER
5.1 Semantic Data Integrity
Goal
At each point in time, the database has to reflect dependencies and rules of the real world as precisely as possible => Data Integrity
Applications should be focused around their respective functionalities and not around enforcing data integrity. This allows for a simplified application development and the Data Integrity is enforced at a single point, at the DBS itself.
Types of Integrity Constraints
Static Integrity Constraints have to be guaranteed at any point in time. Those can be primary and foreign key constraints. Application-specfic constraints on an attribute of a tuple, a complete tuple, several tuples of a relation or even on several relations.
Examples:
The discount of a customer must not exceed 50%
The average discount of all customers must not exceed 30%
The overall value of all products in the same storage location must not exceed 1m CHF.
Dynamic Integrity Constraints have to be re-established at the end of a state change. They are dynamic because they depend on current values in the database. (NOT PART OF THIS LECTURE)
The discount of a customer must not be reduced
Customers with a balance below -1000 are not allowed to place a new order
The evaluation of integrity constraints can take place at the end of single operation (SQL Command) or at the end of a transaction (at the end of a sequence of logically associated operations). Because they can be checked at the end of a transaction, constraints might be violated temporarily during the transaction.
If a violation is detected, the DBMS can either not execute the operation, undo it, abort the transaction or execute a failure handling operation to re-establish consistency.
5.2 Views (Virtual Relations)
Goal:
Guaranteeing data integrity is easier with less derived data. For example "balance" is derived from all orders a customer has done. It is easier to just calculate the balance on demand instead of having it explicitly stored.
Example:

Views can be used for simplyfying queries. If a certain information is often needed, it can be stored in a view which can then be used by other queries. Views can be used to define other view.
When a query uses a view, the viewname is automatically substituted with the view definitions for the participating relations. This is done transitively for views that use other views.
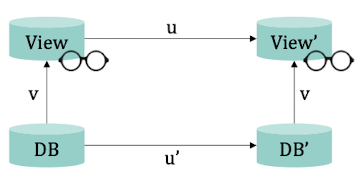
Update on Views:
Insert / Delete operations on tuples in a view are only possible if they can be unambiguously mapped to a tuple of the stored relations.
Example: u is a correct update on a view if there exists exactly one update u' that leads to the same result via the stored relations.
Other Examples:

Check Option for Views
Tuples can be inserted or updated into a view even if the new value does not match the view definition. e.g a View shows all customers from Basel but we can update the location of a customer to Bern.
Now our update is not visible (disappears) from the view.
This can be prevented using the CHECK OPTION which will check updates against the view definition and rejects changes if they do not match.
Views for Data Independence
If the Schema of a DBS changes, a view can provide the "old" schema to applications that depend on it.

5.3 Static Integrity Constraints: CHECK Constraints
Integrity constraints can be specified as part of the CREATE TABLE statement. We can chosse between
Column Constraints for individual attributes
Table Constraints for several attributes of the same relation
We can use the same predicates that we used for the "WHERE" clause for our CHECK constraints.


5.4 Static Integrity Constraints: Referential Integrity
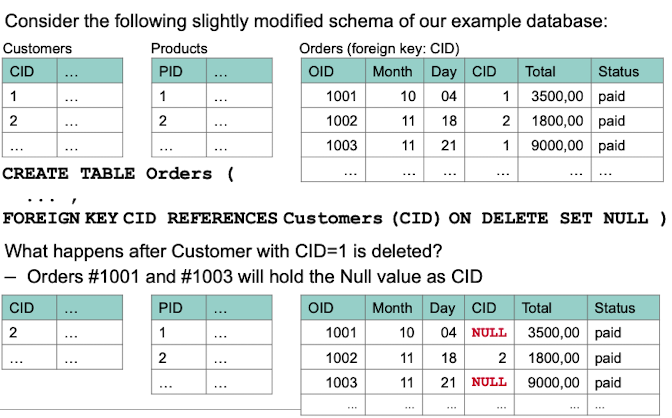
If a relation references another one via foreign keys, we can specify what should happen if the referenced value is deleted.


Deferrability

5.5 Data Privacy and Access Control
SQL supports access control via the GRANT, ON, TO command to control access rights on specific objects in the DBS.



Propagation / Revocation of Access Rights

6.1 NoSQL: Overview
There are alternatives to relational database systems:
Key-value stores - simple data model, "Schema-less schema"
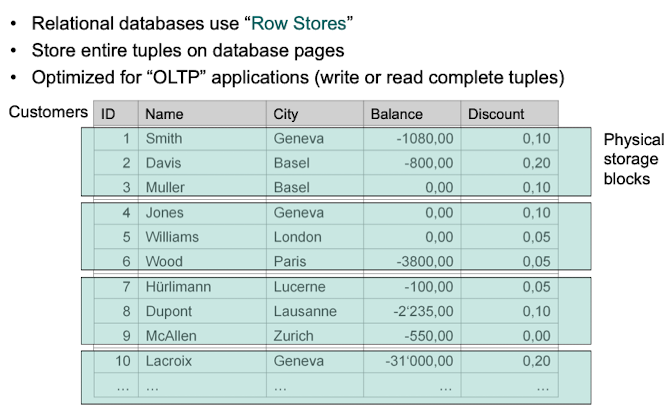
Column Stores - In contrast to traditional row stores, all attributes of the same column are stored on the same database page
Document Databases - Structure of data is specified via XML or JSON
Graph Databases - Systems tailored to graph structures (nodes, edges) and graph algorithms
Object-relational Databases - Extend the relational model with object-oriented concepts
6.2 Key-value Stores

Key-value stores offer get(key), put(key, value) and delete(key) operations to return, insert/change or delete a key-value pair.
Applications:
Web applications: user sessions and user preferences (Key: user ID)
6.3 Column Stores
Applications:
OLAP queries: queries consisting of aggregations across single (or several) attributes
Data Warehouses: analytical queries
OLAP and OLTP
OALP (Online Analytical Processing) is designed for complex querying and analysis of data.
It is used primarily for data mining, business intelligence, and reporting purposes.
Operations focus on read-intensive operations. Queries are often complex and involve aggregations, such as sum, average, and count.
Data is typically updated in batch mode, not in real-time, so it may not always reflect the most current state.
OLTP (Online Transaction Processing) is designed to handle a large number of short online transactions (inserts, updates, and deletes).
It is used for the day-to-day operation of an organization.
Focuses on write-intensive operations. Transactions are typically simple but need to be processed quickly and in large volumes.
Provides high levels of data consistency and integrity due to frequent updates and real-time data processing.
6.4 Document Databases
Each Document is associated with a unique key but in contrast to a key-value store, the value (document) has an inherent structure which is specified either via JSON or XML
JSON:
Supports Objects and Arrays
Example:

XML:
Consists of elements which are delimited by tags which can be nested but must not overlap. Tags may contain attributes.
Example:

Applications:
Store and Query text collections
Metadata management
Structure and store documents needed for exchange between systems
6.5 Graph Databases
Graph databases are well suited data structures to manage networked information. Graph databases can provide sophisticated queries like "Friends of Friends" or give answers to if two elements are "connected" and what the "shortest path" between them is.
Limitations of teh Relational Model
Segmentation: An Object in the application (e.g a Person) has its information distributed (segmented) across a large number of relations (e.g Attributes connected with this Person might be distributed over many tables). When accessing the application Object, the individual parts must be merged via expensive joins.
Artificial Key Attributes: In Order to enforce the uniqueness of tuples, artificial keys have to be assigned. (Keys are not of any use besides identifying a tuple)
Missing behavior: Objects usually have an application-specific behavior which is not taken into account in the relational representation but must be realised outside the DBMS.
Impedance Mismatch: Relational Query Languages are set-orientated but programming languages process only one data record at a time.
RECAP: QUESTIONS:
What are the reasons for using databases for storing data? (and not relying on main memory and/or the file system)
There is an imense amount of data which has to be stored and accessed somehow. Databases help to structure, store and manage this data.
Main memory is not an option because data is lost when the system restarts, crashes or shuts down. Also, Main memory is not large enough most of the time.
Data in file systems may survive restarts, but the file system does not enforce any explicit data format. When everyone just stores his data in "his" file, we end up with many files containing the same data but they might not be equal. => inconsistent, redundant
What is the difference between the intensional and the extensional layer of a database?
The intensional layer describes the structure of the data and the structure of relations. It describes the schema of the database. Changes are expensive and happen therefore only rarely. (all the data needs to be adapted to the new schema)
The extensional layer contains the data itself. It changes very frequently with every transaction which can happen thousands of times per minute.
What is the difference between a Data Definition Language (DDL) and a Data Manipulation Language (DML)
Data Definition Languages describes how data is structured / defined. It sets the schema and constraints. Example: CREATE TABLE
Data Manipulation Languages are used to work with the data in the database. Example: SELECT, INSERT
Why is logical and physical data independence needed?
When the physical layer of a database is changed, for example when a index-search-tree is added for a more efficient search, the logical layers above including the applications should not be affected.
Also when the logical layer is changed, for example when an attribute is added to an Entity in the database, this new attribute should not interfere with exisiting views of the database and be hidden by introducing an appropriate view. (However this is not always the case)
Which level of information modeling do ER models address?
The model the conceptual level of a database which allows structuring the application domain (the mini-world we try to model)
What are the key building blocks of the ER model?
Entity types (objects)
Attribute types (properties of the entities)
Relationship types (relations between entities)
The difficulty is to determine appropriate entity types, attribute types and relationship types.
In which case are role names required in denoting relationship types?
In the case a relationship type is connected to the Entity itself. (Recursion)
For example if a Component is part of another Component, then we need role names to differenciate if a Component is made of other Components or if the Component is a subcomponent of another Component. -- (that's a lot of components...)
How is a relationship identified (or: what should never be added to a relationship type)?
A relationship describes a relation between two or more entities. A relationship type should never have attributes that contain data which is not needed to describe to relation. Also duplicate data which can be derived from another entity should not be part of the relationship type.
What are common cardinalities for relationship types?
1:1 (one to one) - Each Entity relates to either 0 or 1 other Entity.
m:1 (many to one) - Each Entity on the "many" side relates to at most one entity on the "one" side.
m:n (many to many) - Each Entity can relate to several other entities
What are limitations of the ER model?
ER Models get very large and very complex pretty fast...
Which are the two elements of a relation?
A relation consists of its relational schema (structure) and its extension (data)
What does first normal form of the relational model mean?
In first normal form, all attribute values of a tuple in a relation need to be atomic.
What are the key inherent integrity constraints of the relational model?
Entity integrity and refential integrity are the most important integrity constraints and called key inherent integrity constraints.
Entity integrity makes sure that the attributes of a primary key are not null while refential integrity enforces a foreign key to either fully exist (all attributes of the foreign key are not null) or that the foreign key is null.
Name the differences between a candidate key and a primary key.
Candidate keys are sets of attributes of a relation which can uniquely identify each row in a table. There can be multiple (combinations of) attributes that act as candidate key and they can also contain null values.
The primary key is a (manually) chosen candidate key used to identify each row in a table and also to be used as foreign key in other tables. The primary key must be unique, not null but can be a composition of multiple attributes or candidate keys. Usually the primary key is some arbitrary number which does not need to change over the lifetime of the entity.
Which alternatives exist to map type hierarchies in the EERM to the relational model?
Vertical Partitioning: All objects are available as supertype. The primary key of subtypes is also the foreign key of supertypes. Subtypes only contain additional information for the specific subtype.
Horizontal Partitioning: Each Subtype directly contains all the information of the supertype without linking to the supertype (no foreign key).
What determines the key of relationship types when mapped to a relational schema?
The key of a relationship type when mapped to a relational schema is mainly determined by the cardinality restriction of the related entities.
If the cardinality restriction on all edges is (1,*) or (0,*), then the primary key is either a composition of all primary keys of the related entities or a multi-element-subset of it.
If there is an edge with the cardinality restriction (0,1) or (1,1) then the primary key of that related entity is also the candidate key for the relationship type.
In which case does a relationship type in EERM not have to be transformed into a dedicated relation?
If there exists a hierarchic binary relation. If every room belongs to a building but there is no room without a building, then the primary key of the building can just be a foreign key of the room. No extra relation type needed.
Which sub-languages are contained in SQL?
Data definition language and data manipulating language?
Which usages are possible with SQL?
Interactive "stand alone" SQL
Commands for enforcing data integrity and access control
Commands for physical data organisation
Embedded SQL
Integration of SQL in "4th gen language"
What are the differences between the relational model and SQL?
The specification of a primary key is not enforced. If it is specified, the entity integrity is guaranteed though.
If no primary key and no candidate key via UNIQUE is specified, tables may contain duplicates. Hence, tables contain multi-sets ("bags") in contrast to relations as defined by the relational model.
How are natural joins expressed in SQL?
SELECT * FROM Customers NATURAL JOIN Orders
or
SELECT * FROM Customers, Orders WHERE Customers.CID = Orders.CID
What are aggregate functions in SQL?
Aggregate function map a multiset of values to a single value. (MAX, MIN, AVG, SUM, COUNT) all return a single value for the set they are used on.
What does grouping and filtering in SQL do?
Grouping allows us to partition a set of tuples according to the values of an attribute.
Filtering then allows us to filter for specific groups.
What is a correlated subquery - and what makes the correlation?
Multiple Queries can be nested with the "IN" predicate together with the WHERE clause.
Select ... From ... WHERE x IN (Select ... From ... WHERE y in (Select ... From ... ))
If some of the attributes of an inner query correlate to statements of the outer query, it is called a correlated subquery.
Give an example for a query that cannot be expressed in SQL?
Determine the variance of the discounts of all customers
Given a relation with direct flight connections: Determine which airports are reachable independed from number of changes.
However: Such Queries that can not be computed by SQL can be computed by turing compete programming languages. They would need to first get the needed data from the database to do the calculation and then return it separately.
What happens with existing tuples when the schema of a relation is altered?
The new attribute will be set to null for existing tuples. However a second query could calculate and fill the attribute for the existing tuples.
What is the difference between static and dynamic integrity constraints?
Static constraints have to be guaranteed at any point in time. They are inherent to the data model. For example primary key constraints or constraints on a tuple or relation.
Dynamic constraints have to be re-established at the end of a state change. For example some value of an attribute must not be reduced.
When can column constraints be used, when table constraints?
Column and table constraints can be used in the CREATE Table command.
Column constraints constrain the values of a single attribute (column) while table constraints constrain the values of multiple attributes or the entire table.
How can the point in time when foreign key constraints are checked be specified, which options do exist?
Referential Integrity Constraints or foreign key constraints can be checked with the DEFERRABLE and INITIALLY DEFERRED / IMMEDIATE keywords in the constraint block of a command.
We can check the constraints after every statement with DEFERRABLE and INITIALLY IMEDIATE or we can check after an entire transaction when changes are about to be committed with DEFERRABLE and INTIALLY DEFERRED.
Which actions can be executed when referential integrity is violated?
NO ACTION - The query gets rejected, nothing happens
CASCADE - Deletions / Updates are cascaded to every object that refer to the deleted object.
SET NULL or SET DEFAULT, set the values of the foreign key in other objects that refer to the deleted object to NULL or the default value specified.
Name three different reasons why views are important concepts on databases?
Reduction of derived data stored explicitly. This makes it easier to guarantee data integrity.
Data Independence can be guaranteed with the help of views. If the schema of some relation is changed, a view can still provide the "old" schema to applications that depend on it.
Views can be used to refine access rights by giving access only to a view.
When can data be updated via a view?
Data can be updated directly via a view if and only if there exists exactly one operation that results in the same outcome on the explicitly stored relations. Usually, data in views that is derived from multiple attributes can not be changed because its unclear what exactly changed. (e.g "Balance" can not be changed since it is derived from all transactions and its unclear which transaction led to the change in the balance)
How can access rights be specified in a database system?
Access rights can be given with the GRANT command. Access rights are managed with users. Each user from a database can have different rights.
Example: GRANT SELECT ON SomeTable TO Bob
How can data in a key/value store be accessed?
A key value pair can be accessed with the get(key) command. Other commands are put(key, value) and delete(key) to update/insert or delete a pair.
How is the schema of a document database defined?
Document database schemas are usually defined with JSON or XML.
What is the difference between column stores and row stores?
In a row store the data of the entire row is stored together. This is useful in applications where all or most attributes are of interest at a time. Usually row-store is used for OLTP where an entire row is added or read many times.
In a column store, the data of the entire column is stored together. In contrast to row stores it is now easy to access one attribute of all rows instead of all attributes of one row. Usually column stores are used for OLAP where single or a few attributes are compared for all entries.
What is the difference between OLAP and OLTP?
OLAP, Online Analytical Processing is mainly used in business intelligence and focuses on the comparison of single attributes for all entries. Queries usually consists of complex aggregate functions with SUM, AVG or COUNT. It is therefore also updated in batch mode in a specified time interval and not real-time.
OLTP, Online Transaction Processing is used for fast and efficient transactions, i.e entire rows (entries) are added very frequently. The focus lies in performance of write-intensive operations. Provides a high level of data integrity due to real-time updates.
What does the term "impedance mismatch" mean?
Programming languages store data differently than most DBMS. For example OOPL store data as objects with functions and attributes while relational databases store data in tables with rows and columns.
Also OOPL have concepts like Polymorphism and Inheritance which are difficult to represent in relational models.
Also, Relational Query Languages are often set-oriented while programming languages process one task at a time.
Where and how is data stored in a graph database?
Graph Databases store data in Nodes and Edges (which connect nodes). Nodes and Edges are also labeled to define their type. (e.g Node => likes => Node or Node => dislikes => Node)
What is the difference between a tuple table and an object table?
Attributes of a tuple table can be tuples, collections, tables, embedded objects etc...
Attributes of an object table are user defined types. Just like user defined objects (classes) in OO Langauges.
What is a subtable?
In Object-Relational Databases, one attribute a Table can reference an entire Table (instead of just one tuple of another table like with foreign keys)
This referenced table is then called a sub-table
How can different invocations of recusive SQL be linked to each other?
